Mahout project would be logical place for stochastic method for MapReduce platform to appear. However, as of last year, the work on this method has appeared to be stalled somewhat. The problem was appealing in engineering and mathematical sense to me, so I decided to get on it. The implementation I arrived at can be obtained via my github repository and also being integrated into Mahout thru MAHOUT-376 and MAHOUT-593.
So, to the gist of it.
Modified SSVD method
First thing I did, I modified original algorithm just a tiny bit to make it more practical for MapReduce front end computations.
(There's great linear algebra visualizations here that might help visualize some of the steps, although terminology is sometimes odd compared to what found in most matrix computation textbooks),
We find our basic discussion of stochastic projection in [Halko,et al]. The following is modified stochastic SVD algorithm:
U is m × k, Σ is diagonal matrix containing k singular values; V is n × k.
1. Create seed for random n×(k + p) matrix Ω . The seed defines matrix Ω using Gaussian unit vectors per one of suggestions in [Halko, et al].
Creating stochastic projection basis :
2. Y=AΩ, Y is m × (k+p).
Now Y spans our random subspace. I guess, intuitively, my understanding is that Y is quite likely to be closely aligned with most most of the vectors in A, so that we are not loosing major factors in A (SVD problem is practically the same as factorization problem).
Next, we orthonormalize the subspace spanned by Y using 'thin' QR:
3. Column-orthonormalize Y → Q by computing thin decomposition Y = QR.
Now align original data with our reduced space basis :
4. B=QΤA. B is ( k + p ) × n.
Original algorithm proceeds with computing SVD of B. But matrix B is as wide as original matrix A and it is also dense, which means that for k+p being something like 1000 and A width (n) in the area of 10e+8, double precision arithmetics, we need 8e+11 bytes of RAM, or 800Gb. Not very practical, for scale, huh. Besides, since SVD of B is going to happen in the frontend, it is not a MapReduce process anymore and any benefit from parallel cloud computations is gone here. It is going to take quite a lot of time to compute this. So I changed the following steps to reduce problem size even further and proceed with an eigensolution instead of SVD:
5. Compute eigensolution of a small symmetric matrix BBΤ
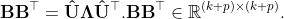
And just like that we just reduced the size of the problem to (k+p) × ( k+p ), i.e. taking example above, from 800 Gb to just meager 8 Mb. We can solve 8 Mb -large eigenproblem in the frontend with any stock high-precision solver in a matter of seconds (if not fractions of a second).
Computing BBΤ with help of a MapReduce process is also very quick (by mapReduce standards, since it takes about 20 seconds just to set up all the mappers). But for the problems of significant size and good sized cluster we could really push the boundaries of the problem size with this approach in cases where Lanczos or RAM-only solver may not be practical (and MPI framework is too expensive).
There is a danger of potentially loosing some precision here, but in practice i did not see any. 8Mb is probably enough bits to represent millions and millions of soft clusters. Besides, in all my experiments with a reasonable sized problem that i could still fit in RAM to verify with a stock solver, stochastic projection errors were significantly higher than any errors coming from rounding errors in double arithmetic.
Restoring right and left eigenvector matrices is then easy.
6. Singular values Σ=Λ0.5.
7. If needed, compute
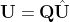
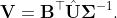
Creating stochastic projection basis :
2. Y=AΩ, Y is m × (k+p).
Now Y spans our random subspace. I guess, intuitively, my understanding is that Y is quite likely to be closely aligned with most most of the vectors in A, so that we are not loosing major factors in A (SVD problem is practically the same as factorization problem).
Next, we orthonormalize the subspace spanned by Y using 'thin' QR:
3. Column-orthonormalize Y → Q by computing thin decomposition Y = QR.
Now align original data with our reduced space basis :
4. B=QΤA. B is ( k + p ) × n.
Original algorithm proceeds with computing SVD of B. But matrix B is as wide as original matrix A and it is also dense, which means that for k+p being something like 1000 and A width (n) in the area of 10e+8, double precision arithmetics, we need 8e+11 bytes of RAM, or 800Gb. Not very practical, for scale, huh. Besides, since SVD of B is going to happen in the frontend, it is not a MapReduce process anymore and any benefit from parallel cloud computations is gone here. It is going to take quite a lot of time to compute this. So I changed the following steps to reduce problem size even further and proceed with an eigensolution instead of SVD:
5. Compute eigensolution of a small symmetric matrix BBΤ
And just like that we just reduced the size of the problem to (k+p) × ( k+p ), i.e. taking example above, from 800 Gb to just meager 8 Mb. We can solve 8 Mb -large eigenproblem in the frontend with any stock high-precision solver in a matter of seconds (if not fractions of a second).
Computing BBΤ with help of a MapReduce process is also very quick (by mapReduce standards, since it takes about 20 seconds just to set up all the mappers). But for the problems of significant size and good sized cluster we could really push the boundaries of the problem size with this approach in cases where Lanczos or RAM-only solver may not be practical (and MPI framework is too expensive).
There is a danger of potentially loosing some precision here, but in practice i did not see any. 8Mb is probably enough bits to represent millions and millions of soft clusters. Besides, in all my experiments with a reasonable sized problem that i could still fit in RAM to verify with a stock solver, stochastic projection errors were significantly higher than any errors coming from rounding errors in double arithmetic.
Restoring right and left eigenvector matrices is then easy.
6. Singular values Σ=Λ0.5.
7. If needed, compute
8. If needed, compute
No comments:
Post a Comment